【MapReduce】---- MR 框架原理 之 Shuffle机制
本文共 581 字,大约阅读时间需要 1 分钟。
文章目录
♑ 定义
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。
♑ Map方法之后Shuffle过程
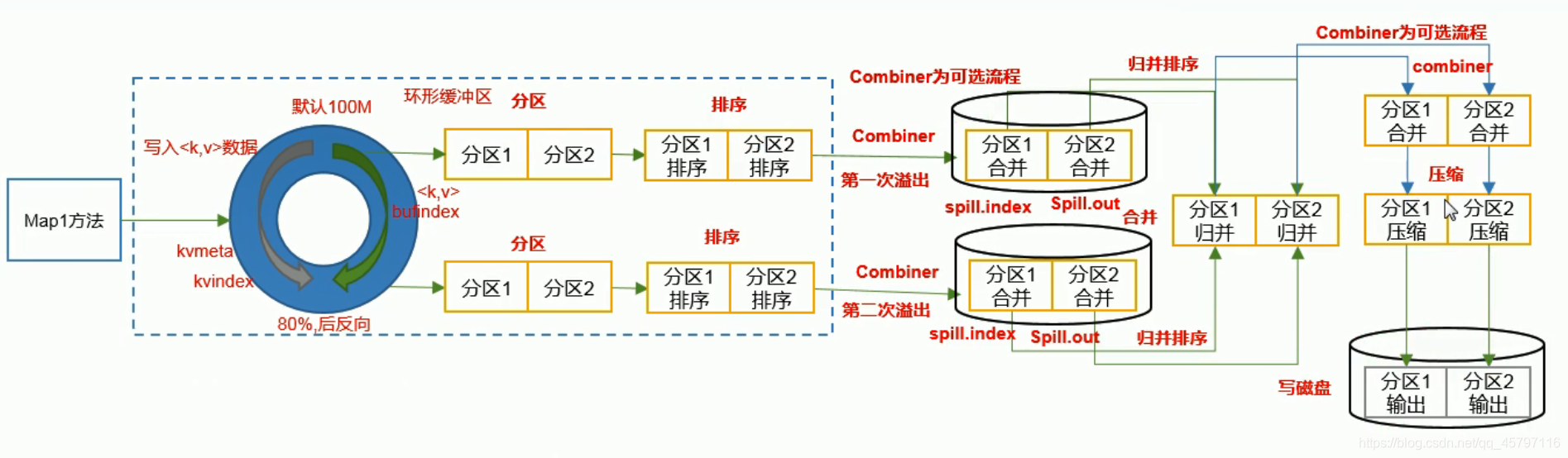
♬ 分区
- 在溢写之前对环形缓冲区中的数据集进行分区操作
♬ 排序
- 在溢写之前对环形缓冲区中分区的数据集进行排序,按照分区进行
♬ Combiner(可选)
- 在溢写到磁盘之前,如果是汇总操作,可以利用Combiner对数据进行分区合并,最终溢写到磁盘上
♬ 分区归并排序
- 将分区上的数据集进行归并,同一分区上的数据集合并,排序(如果符合条件还可以继续进行Combiner合并)
♬ 压缩
- 对处理好的数据进行压缩
♬ 写磁盘
- 将压缩好的数据写到磁盘上,按分区输出
♑ Reduce方法之前Shuffle过程
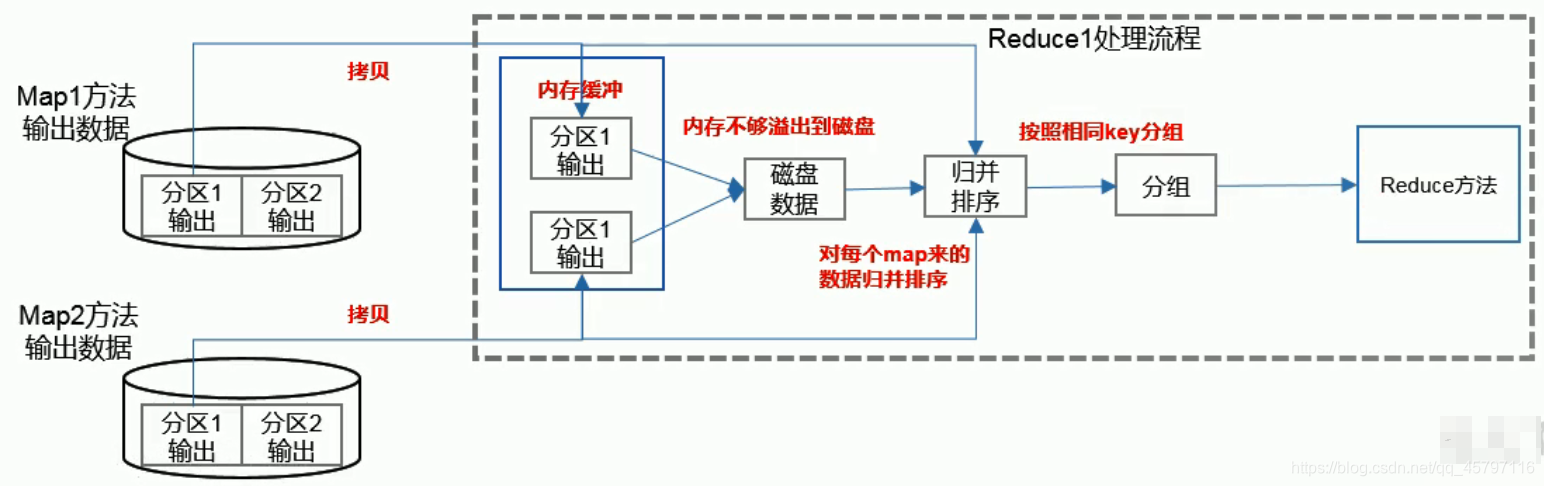
主要包括以下几步:
♬ 拷贝
- 将map处理输出的同一分区数据拷贝到内存中,若内存不够,溢出到磁盘中(同时开启一个RecuceTask来处理该分区的数据)
♬ 归并排序
- 将内存和磁盘上的数据集进行归并,也就是在每个开启的ReduceTask中,对从不同MapTask中拉取过来的相同分区的数据进行合并,之后对每个ReduceTask上合并的总数据集再进行排序。
♬ 分组
- 对归并好的数据按照相同的key进行分组,等待reduce()来对同组数据进行处理,也就是相同key的数据进入同一个reduce()方法。
转载地址:http://ckeq.baihongyu.com/
你可能感兴趣的文章